
Voice Agent Telemetry: Where Every Millisecond Counts
When building real time voice systems, there's a moment we've all felt. That pause after you finish speaking, waiting for the AI to respond. It's a fraction of a second, but it breaks the flow. That delay is what separates fast enough from real time.
At Rapida, we're obsessed with those milliseconds. Because in conversational AI, latency isn't just a metric. It's the difference between natural and robotic.
When a Conversation Starts
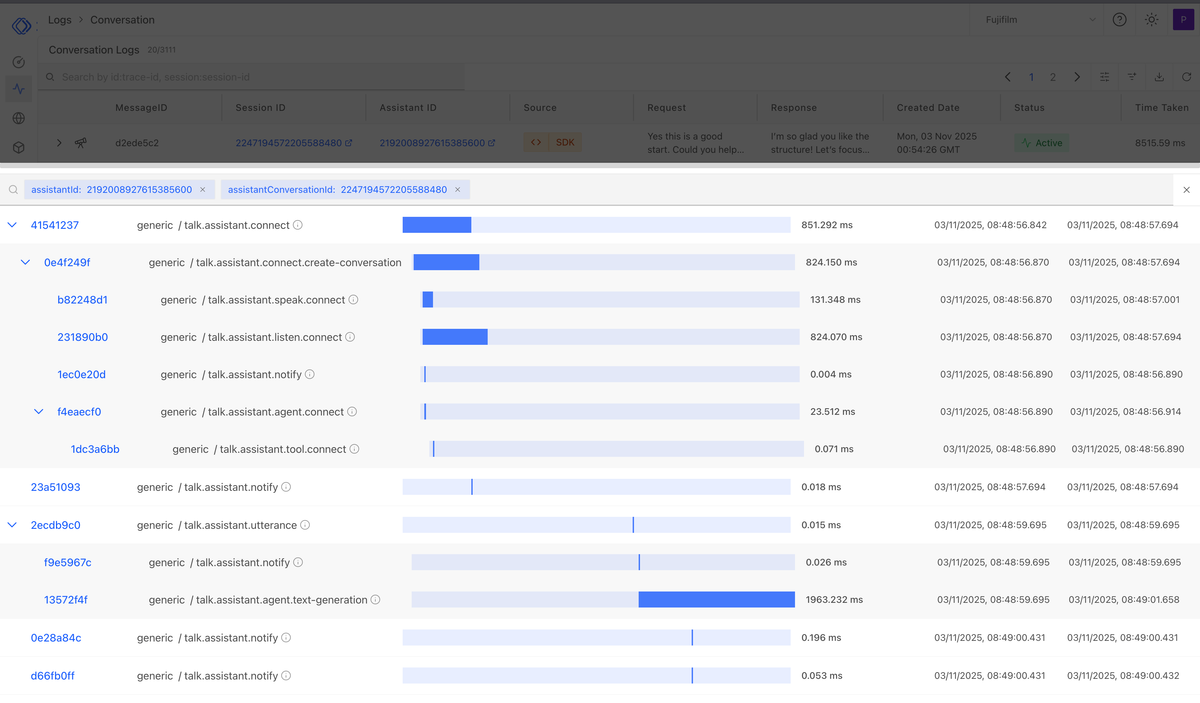
The moment a user starts speaking, the system has to get ready before it can actually respond. That means creating connections to different parts of the stack. First, it connects to the STT system to start streaming audio. At the same time, it prepares the TTS system so it can generate voice when needed. It also connects to the agent that manages context, memory, and orchestration.
Each connection takes time. Network calls, authentication, and session setup can add up, often taking between 200 milliseconds to a second before the system is fully ready. Measuring this warm up time is critical, because it sets the baseline for how fast the conversation can actually start.
| Component | Connection Type | Avg. Time (ms) | Notes |
|---|---|---|---|
| Agentic system | WebSocket | 120–180 | Session handshake and authentication |
| STT (Deepgram) | WebSocket | ~500 | No DNS cache, depends on region |
| TTS (Cartesia / ElevenLabs) | WebSocket | 300–600 | No DNS cache, varies by region and network |
| VAD / EOS | Local init | 30–50 | Loading model and setting thresholds |
Latency During a Live Conversation
Once the system is warmed up, every turn adds its own delays. Each time a user speaks, several components work together in real time: STT streams audio, the agent interprets the transcript, optional external tools or memory lookups are triggered, and TTS generates the response.
Even with warm up done, each of these steps introduces latency. In phone or live call scenarios, every 100 ms matters. Users can start talking over the system if the AI doesn't respond quickly, which can trigger unnecessary LLM calls or tool invocations. This increases compute, token costs, and makes the interaction feel sluggish.
| Component | Avg. Time (ms) | Notes |
|---|---|---|
| STT (Deepgram streaming) | 150–250 | Partial transcript per audio chunk |
| LLM inference | 200–400 | Depends on token count and model size |
| TTS (Cartesia / ElevenLabs) | 120–200 | Streaming voice generation |
| Tool / Memory calls | 50–150 | Optional, depends on integration |
| VAD / EOS | 30–50 | Local inference to detect turn end |
In multi turn conversations, these delays accumulate. Optimizing each component is essential for real time, natural feeling interactions.
Reducing Latency: Engineering Real Time Pipelines
At Rapida, reducing latency isn't just about faster models. It's about how the system is built. We use Go for the backend because its concurrency model makes it easy to run multiple tasks in parallel.
When a user speaks, STT, LLM inference, and TTS streams are handled in separate goroutines, allowing them to work simultaneously. That means the system can start generating parts of the response while the rest of the transcription is still coming in.
We also keep connections to STT, TTS, and the agentic system persistent, avoiding repeated handshake delays. Local VAD/EOS routines run in parallel as well, quickly detecting turn ends without waiting for remote calls.
Using Go's channels and lightweight goroutines, we can coordinate streaming audio, inference, and response generation efficiently. Even with multi region deployments, this approach keeps per turn latency under 500 ms in most real world calls.
Bringing It All Together
In real time voice AI, every millisecond counts. From the moment a conversation starts, warm up time for STT, TTS, agent, and VAD/EOS sets the baseline. Once the conversation is live, each turn adds more latency from transcription, inference, speech generation, and optional tool calls.
At Rapida, we combine persistent connections, Go based parallel routines, and local processing for VAD/EOS to minimize delays. The result is a system that responds fast and consistently, even in multi turn conversations and multi region deployments.
| Stage | Avg. Time (ms) | Notes |
|---|---|---|
| Warm up (connections) | 950–1300 | STT, TTS, agent, VAD/EOS |
| Per turn processing | 400–500 | STT, LLM, TTS, tool calls, VAD/EOS |
Optimizing both warm up and per turn latency ensures natural, responsive interactions. Every millisecond shaved off makes the difference between an assistant that feels robotic and one that feels truly conversational.
At Rapida, we're continuously improving the stack so that the system is not just fast but predictable and reliable. We're laying the groundwork for next generation real time voice AI.
