Agentic Engineering: Technically Correct, Contextually Naive
A startup CEO recently posted that his team generated a million lines of code with AI agents in a quarter. After twelve months shipping a production voice AI platform with AI coding agents, I've started paying attention to a different question: what happens after the code is written?
Agents don't carry context
When a human engineer writes code, they carry context. They remember last week's production incident. They know which customer has a latency constraint that isn't in any spec.
They know that Twilio retries webhooks aggressively when responses are slow, and you need idempotent handlers. Their code reflects accumulated judgment not just what's technically correct, but what's contextually right.
Agents don't work this way. Each generation starts fresh. An agent writing a telephony webhook handler today has no memory of the duplicate-event bug you fixed last month. It generates code that's technically correct — passes linting, passes tests, matches the schema and contextually naive.
For the first feature, this is fine. By the tenth deploy, you're shipping code that ignores everything production taught you from the first nine. Each unencoded lesson becomes tech debt and at agent-generated volume, it compounds fast.
The data backs this up. A 2026 study of Cursor adoption found that agentic AI raises cognitive complexity by 25% and nearly doubles security warnings. These aren't failures of code generation. They're failures of context accumulating at machine speed.
Why gates alone don't scale
The instinct is to add more pre-deploy checks. More tests. Stricter reviews. Tighter linting. And that helps — up to a point.
The surface area of what could go wrong grows faster than your ability to write checks for it.
Pre-deploy gates catch the predictable failures. They miss the contextual ones that only surface with real traffic, real data, and real provider behavior.
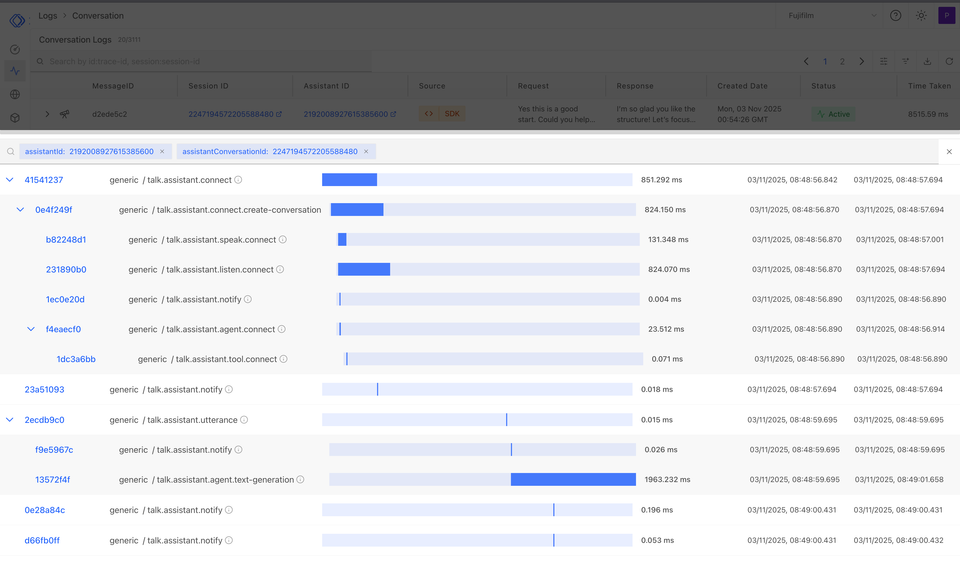
We experienced this directly at Rapida. An agent generated a webhook handler for inbound telephony calls. The code was clean. It parsed the provider's payload correctly. It created the conversation record. It passed every test. In production, our monitoring showed duplicate call sessions being created for the same inbound call. The telephony provider retried its webhook when our response was slightly delayed, and the handler processed the same call twice — two conversation records, two media sessions racing against each other.
No pre-deploy gate would have caught this. The code was correct. The context was missing.
An engineer who'd dealt with that provider before would have made the handler idempotent from the start. Not because they're smarter — because they carry scar tissue the agent doesn't have.
The feedback loop
We fixed the duplicate events the same day. But the fix wasn't the point.
After that incident, we added idempotency constraints to the webhook contract. Now when agents generate webhook handlers, they must follow that contract. Duplicate events can't happen again — not because we review harder, but because the constraint is encoded into the system.
This is the pattern that matters: what you learn in production gets encoded back into the constraints the agent works within. The contracts get tighter. The gates get smarter. The rules accumulate. The system carries the context so the agent doesn't have to.
It's not a linear pipeline — write, test, ship, hope. It's a loop. Production teaches the system, and the system constrains the next generation.

What this changes
This shifts what engineering looks like when agents write most of the code. The core skill isn't code generation — that's commoditized. The core skills are:
Constraint design
Deciding what the agent must satisfy before the code is valid. Not just type signatures and test coverage — structural invariants like "a call context can
only be claimed once" or "disconnection signals must be idempotent."
These aren't documentation nobody reads. They're contracts the agent must satisfy before the code compiles or the checklist passes.
Fast detection
Building the monitoring that surfaces contextual failures quickly. The duplicate-session bug wasn't caught by tests — it was caught by production metrics within
hours.
The faster you detect, the smaller the blast radius, and the sooner the lesson enters the loop.
Encoding judgment
Turning a one-time fix into a permanent constraint. At Rapida, the webhook incident didn't just produce a fix.
It produced constraints at three levels:
- State machine that prevents duplicate sessions,
- Base abstraction that gives every new streamer idempotent behavior for free
- Developer guide that encodes the full pattern for agents building the next provider. That's the difference between fixing a bug and making the system smarter.
The investment isn't in reviewing everything manually. It's in making the system accumulate context over time — so you can ship faster with higher confidence, not slower with
more caution.
Where the edges are
This problem is early. The patterns are emerging, and the industry is starting to name it — Tomasz Tunguz calls it "agent ops," Harrison Chase describes it as a fundamentally different observability challenge. A few areas where we see the edges:
- How specific should constraints be? Too broad and they restrict the agent unnecessarily. Too narrow and you're writing a rule for every edge case. Finding the right level of abstraction is ongoing work.
- How do you know the loop is working? We track whether the same class of issue recurs. If it does, the constraint wasn't encoded well. But measuring "issues that didn't happen" is inherently hard.
- When does the system have enough context? At some point, the accumulated constraints should make the agent's output reliably safe for your domain. We're not there yet — and from what we can tell, neither is anyone else.
The code generation was never the hard part. The hard part is building a system that learns from what breaks — so the agents carry the context even when they can't carry the memory.