The Quality gap nobody talks about
The constraint
We served 8 enterprise clients with different compliance requirements, different business logic, and different quality standards.
And, our Product, Design & Engineering (PDE) team was two people, Prashant and I.
No QA team. No SRE. No engineering manager reviewing pull requests. Every line of code that reaches production passes through automated systems — because there's nobody else to catch it.
This post is about the architecture that makes that work: the quality gates, the multi-repo strategy, the metrics we track, and why the industry's conversation about AI-assisted engineering is missing the most important part.
The quality gap
Everyone's celebrating speed. Google's 2025 DORA research found that AI-assisted teams merge 98% more pull requests. But delivery metrics stayed flat. Bug rates climbed 9%.
This isn't a fringe finding. CodeRabbit's analysis of 470 pull requests found AI-generated code carries 1.7x more issues than human-written code, with 3x the readability problems and 2.74x the security vulnerabilities.
We're generating code faster than we can verify it.
And when you're two people serving enterprise clients, that's not a research finding. It's a contract risk.
The conventional answer to serving multiple clients from a small team is feature flags — one codebase, toggle features per client. We killed that idea immediately.
Three reasons why feature flags don't work
- Identity in isolation - Enterprise clients need provable code and data isolation for compliance audits. Feature flags share at runtime. When an auditor asks "can you prove Client A's logic never executes in Client B's context?", feature flags make that proof difficult. Separate codebases make it trivial.
- Divergent logic, not toggles - Feature flags turn things on or off. Our clients don't need toggles — they need fundamentally different modules. Fujifilm's compliance rules are hundreds of lines different from TPC's workflow logic. That's not a flag. That's a different implementation of the same interface. Encoding that inside Feature flag conditionals create spaghetti. Separate repos allow clean module injection.
- Testing explosion - Ten clients with ten feature flags means 2^10 possible system states. That's 1,024 combinations to test. By using separate repos with a core merge, we keep the testing surface linear: Client + Core. Not exponential.
What we built: Hub and Spoke
Our architecture is a hub-and-spoke model with two layers of automated quality enforcement. The spokes are client-specific. The hub is production. Quality gates sits at both levels.
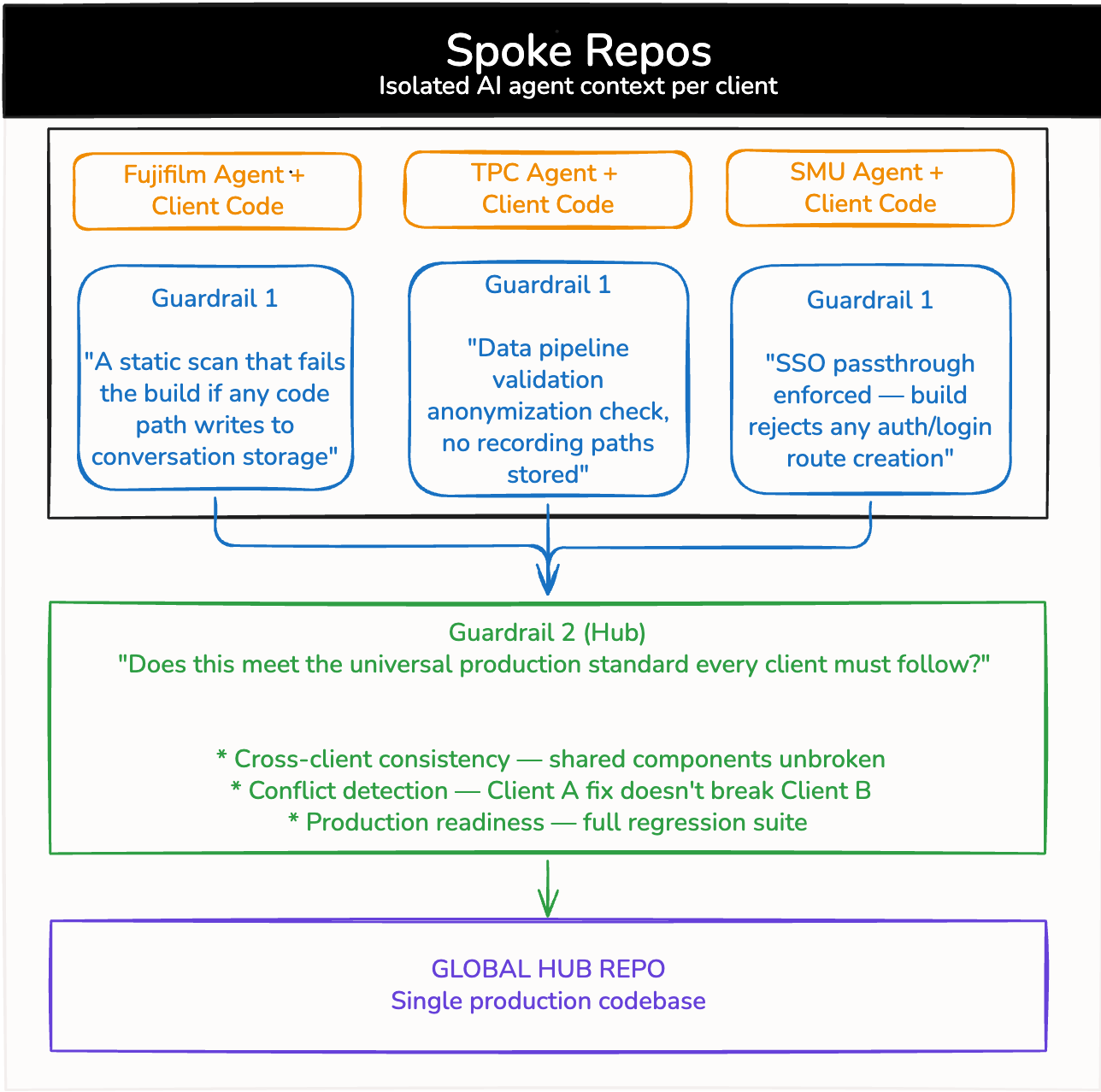
Layer 1: Spoke Gates (Client-Specific)
Each client has its own spoke — a repository carrying its own context: compliance requirements, business logic, and quality gates tailored to that client's needs.
When code is generated or modified in a spoke, it passes through client-specific validation before it can merge.
- Fujifilm required zero conversation storage — their data compliance policy was absolute. The spoke gate runs a static scan that fails the build if any code imports ConversationStore, writes to the conversations table, or creates a schema migration that touches session logs. The no-storage rule isn't a configuration flag. It's a
build failure. - TPC allowed anonymized conversation storage but prohibited recordings and required integration with their HRMS. The gate runs a data pipeline validation — any stored conversation must pass a PII scrubber before write, and any code that creates recording_url or audio_path fields is rejected. A schema contract test validates the
HRMS integration adapter against TPC's API spec on every merge. - SMU was an internal product for their own staff, which meant no external logins — all authentication had to pass through their SSO. The gate rejects any /auth/login or /auth/signup route creation, fails the build if local auth libraries appear in dependencies, and ensures no password_hash fields exist in any database migration
The AI agents generating code in these repos aren't generic. They carry client-specific context — they understand what "correct" means for that particular customer. Fujifilm's rules don't bleed into SMU's repo. The isolation is structural, not just logical.
Layer 2: Hub Gates (Global)
We can't maintain eight codebases. We're two people. So we don't.
All three spokes merge into one hub — a global production codebase — through a second layer of quality gates. Hub gates enforce three things:
- Cross-client consistency — shared components behave the same way across all clients. Before any spoke merges into the hub, impact_analysis.go asks one question: will this change break a different client? It reads the diff, traces which pkg/ paths each client actually calls, and reasons against each client's requirements from their client-context/. A change that's perfectly valid for TPC's workflow logic might silently violate Fujifilm's audit trail requirement. Static analysis doesn't catch that. The agent does — because Fujifilm's compliance requirements are in the prompt.
- Conflict detection — when a gate fails in the hub, failure_analysis.go asks a different question: why did this pass in the spoke but break here? The agent gets the full CI output, the exact assertion and stack trace, the last known good hub state, and which other spoke merged recently. If SMU merged two hours before TPC's test failed, that's the first place to look. The agent generates a scoped root cause and a fix suggestion, posted directly as a PR comment.
Production readiness — two prompts. One preventive, one diagnostic. Together they replace the engineering manager reviewing the PR and the QA engineer triaging the failure — which, for a two-person team serving enterprise clients, is the only way the system works.
Three spokes in. One hub out. Automated.
Why this maps to established patterns
This isn't a novel architecture. AWS's Well-Architected Generative AI Lens describes a similar tiered approach: tenant-specific policy enforcement at the first layer, global regression and security gates at the second. OpenAI's harness engineering team enforces layered domain architecture with strict dependency directions — code can only depend "forward" through fixed layers, validated mechanically via custom linters.
What's different about our implementation is the constraint: two people. The automation isn't a nice-to-have. It's the only way the system works.
The metrics that matter
The metric that tells you this works isn't lines of code. It's not even pull requests merged — DORA's own research showed that metric is actively misleading when AI inflates PR counts without improving delivery.
We track two things:
- Cycle time (commit to merge) — how fast client-specific work flows through spoke gates, into the hub, through hub gates, into production. When your quality gates are automated, cycle time tells you whether the discipline layer is helping or hurting velocity.
- Time to UAT (merge to customer validation) — how fast code is in front of the customer being tested. This connects engineering output to business value. Code that passes all quality gates but takes two weeks to reach customer validation isn't shipping — it's queuing.
The research validates the approach
The discipline layer isn't just intuition. Blyth et al. (2025) ran an experiment wrapping AI-generated code in an iterative static analysis feedback loop — scan for
violations, feed them back into the model, fix, repeat. After up to 10 iterations: security vulnerabilities dropped from over 40% to 13%. Readability violations from
over 80% to 11%. Reliability warnings from over 50% to 11%.
Our tiered quality gates are this same principle at the CI/CD level. The spoke gates are the first feedback loop — client-specific violations caught before merge. The
hub gates are the second — global violations caught before production. Each layer catches what the previous layer missed.
The gap isn't in the model's capability. It's in the process wrapping the model.
What we're still learning
This system works for 8 enterprise clients with a two-person team. We don't know yet how it scales to 50. The tiered gates add latency — every layer of validation is time that code isn't in production. So far, the trade-off is worth it: slower merge, fewer incidents.
We also don't know how the architecture evolves as AI agents become more capable. Today, the agents need client-specific context injected explicitly. Tomorrow, they might infer it. That changes the gate design fundamentally.
What we do know: building fast is the easy part now. Everyone can do it. The teams that win will be the ones that built the discipline layer — the quality gates, the tiered enforcement, the metrics that measure value, not volume — before they needed it.
Everyone talks about small teams doing more. Nobody talks about what "more" actually costs without the systems to govern it.