Rapida Voice System Performance Benchmarks
This post documents latency and scaling behavior of Rapida under sustained concurrent voice traffic. The intent is to show how the system behaves under realistic production conditions rather than demo workloads.
Rapida is an open source voice orchestration system designed to manage real time audio streaming, speech recognition, language model execution, and speech synthesis with full visibility into each stage.
Measurement scope
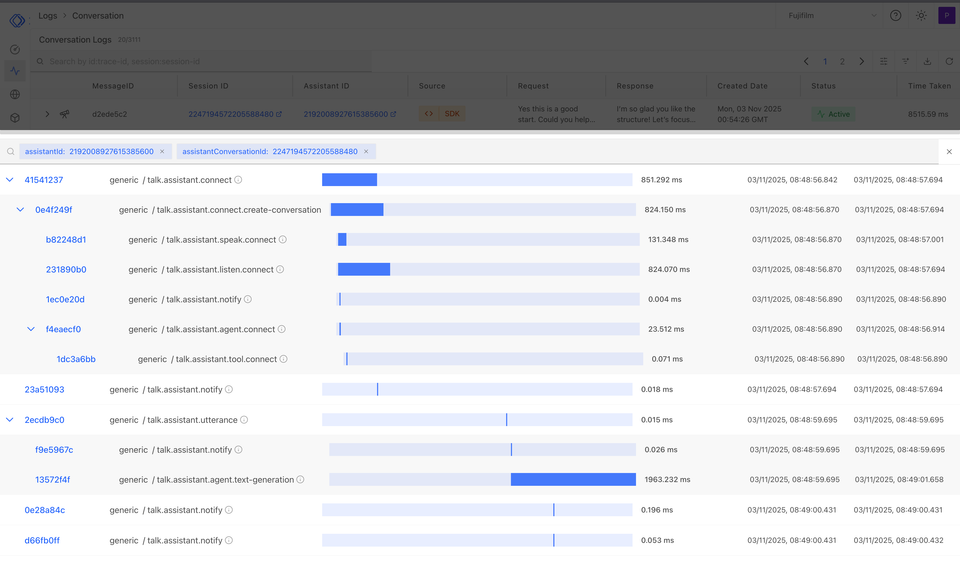
Latency was measured across the full request path observed by a caller.
Audio ingestion from telephony into the orchestrator
Time to first partial transcript from speech recognition
Time to first token from the language model
End to end response time including synthesized audio
All values are reported as p50 and p95. Mean values were not used because they hide tail latency.
Performance benchmarks
Latency versus concurrent calls
| Concurrent calls | Audio ingestion p50 / p95 | STT partial p50 / p95 | LLM first token p50 / p95 | End to end p50 / p95 | System notes |
|---|---|---|---|---|---|
| 10 | < 20 ms / < 30 ms | 120 ms / 300 ms | 300 ms / 800 ms | < 1.2 s / < 1.6 s | Single orchestrator instance with no queueing |
| 50 | < 25 ms / < 40 ms | 150 ms / 350 ms | 400 ms / 900 ms | < 1.3 s / < 1.7 s | Speech workers become CPU bound |
| 100 | < 30 ms / < 60 ms | 180 ms / 400 ms | 500 ms / 1000 ms | < 1.4 s / < 1.8 s | Speech layer scales horizontally |
| 250 | < 40 ms / < 80 ms | 220 ms / 450 ms | 650 ms / 1200 ms | < 1.5 s / < 2.0 s | Queueing visible at p95 |
| 500 | < 60 ms / < 120 ms | 300 ms / 600 ms | 900 ms / 1600 ms | < 1.8 s / < 2.4 s | Backpressure active |
| 1000 | < 100 ms / < 200 ms | 450 ms / 900 ms | 1400 ms / 2400 ms | < 2.5 s / < 3.5 s | System saturated without additional capacity |
Benchmarks were executed on Amazon Web Services in the ap south 1 region.
Kubernetes EKS version 1.28
Orchestrator node type c6i.4xlarge
OpenSearch node type r6g.4xlarge
PostgreSQL high availability r6g.2xlarge
Redis r6g.large
Traffic was steady state with sustained concurrency rather than short bursts.
Observations
At low and moderate concurrency, response latency stays within a conversational range.
Latency increases gradually as load grows. There are no sudden collapse points where the system becomes unstable.
Speech recognition saturates before language model execution, which allows targeted scaling instead of scaling the entire stack.
Queueing and backpressure are visible in metrics before they impact most calls. This makes capacity planning predictable.
Why this matters
In production voice systems, the key questions are not peak throughput or demo latency.
- Where is time spent
- When does queueing begin
- Which component saturates first
- How p95 behaves as concurrency grows.
Rapida exposes these details directly through metrics and logs. Nothing is hidden behind managed abstractions.
Voice systems fail more often due to orchestration, scheduling, and lack of visibility than due to model quality.
Rapida focuses on these layers.
You can run it yourself.
You can reproduce these benchmarks.
You can change the system when it does not fit your needs.
Source code and documentation are available at
github.com/rapidaai/voice-ai