
Evals aren't testing, they're teaching
Most of us who built products before LLMs carry the same instincts into it. You spec it, you build it, you test it, you ship it. QA sits at the end. We carried that instinct into building with LLMs — and it broke.
At Yuuki*, we built an AI coaching product for first-time managers. To evaluate whether Yuuki was actually coaching well, we did what any product team would do — we designed rubrics. Ten criteria: empathy, action-orientation, whether the coach made the user think. Each scored zero to ten.
My nine was my co-founder's six. The LLM judge scored a seven that meant something different from both. Three months of data, and we couldn't tell whether the system was improving or our calibration was drifting.
Our first eval system back in January 0f 2024. Ten criteria, scored zero to ten. Two months of this and we couldn't tell if the product was improving.
The instinct is more criteria, more granularity, tighter rubrics. That makes it worse. Every additional dimension is another surface for disagreement. We weren't building a better evaluation. We were building a more elaborate way to disagree.
Binary
We switched to yes or no. Is this response empathetic? Yes or no. Does it push the user toward action? Yes or no. No more debates about whether something is a six or a seven.
Hamel Husain, who's rolled out evals across thirty-plus companies, landed on the same approach — binary pass/fail with domain expert judgment. We weren't the first to arrive here. But we arrived here the hard way.
Binary forced clarity. When you can only say yes or no, you have to know what you're actually looking for. The vagueness that hid inside a scale has nowhere to go.
The mechanism
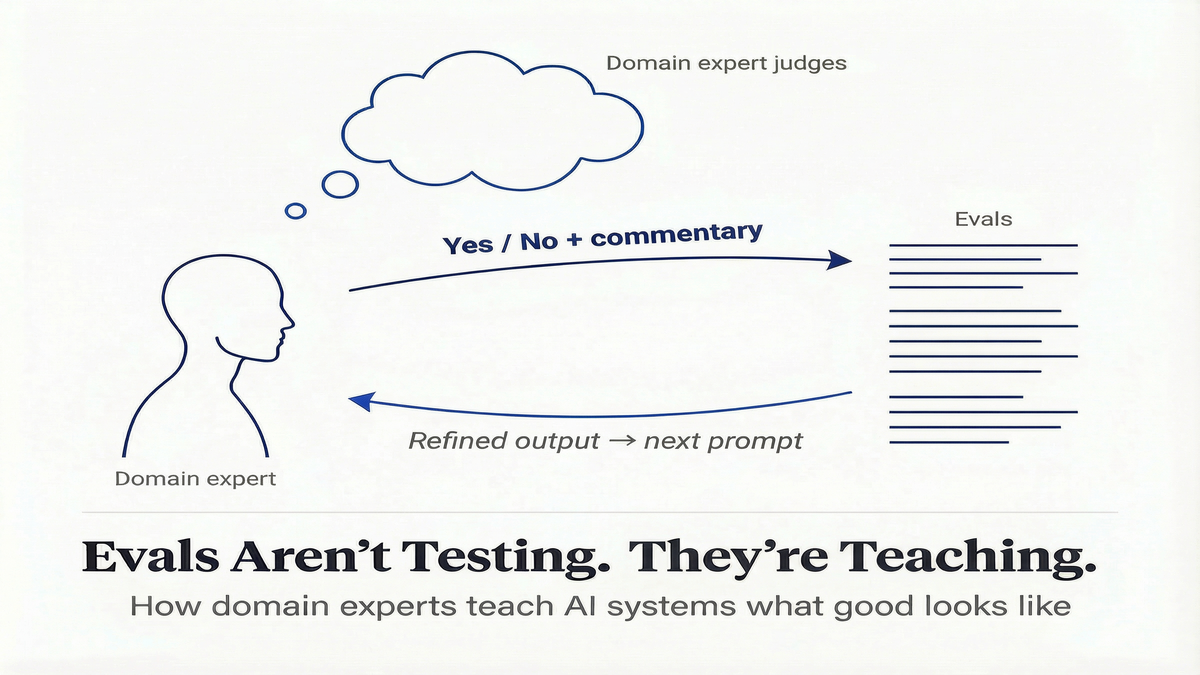
Every yes or no came with a line of commentary. Why it passed. Why it didn't. That commentary fed directly into the next version of the prompt.

What replaced it. Pass/fail with one line of commentary. That commentary fed directly into the next prompt.
Here's what that looks like in practice. A coach reviews an AI response and marks it "Not Ok." Her commentary: "The agent gave advice before asking a single question about the situation. A good coach would ask a follow-up first." That critique becomes a constraint in the next prompt version: always ask a clarifying question before offering a suggestion. The next generation of responses follows the constraint. The coach reviews again, refines further, and the system gets closer to what good coaching actually looks like — not in theory, but in her expert judgment.
Our coaches weren't reviewing outputs after the fact. They were teaching the system what "good" means, one judgment at a time.
What the evals were actually teaching
I used to think evals were how you check quality after building. What I didn't expect is that the evals weren't just teaching the model. They were teaching us.
What our product standards actually are. What our domain experts intuitively know but haven't said out loud. What "good" means in terms specific enough to build on.
This matters because without the eval process, those standards stay locked inside people's heads — implicit, inconsistent, and impossible to encode into the product. With it, every judgment becomes a building block. The system gets better not because you retrain the model, but because you keep showing it what "good" means in your specific domain — through the evals themselves. That's a product that learns from use, not one that's frozen at launch quality.
It's like asking an expert cook for the recipe. They can't give it to you. They just know — a pinch of this, a little more of that, done when it feels right. You have to watch them cook, taste the dish, and ask "why did you add that?" The answer comes out in the doing, not in advance.
That's what the eval process does. The criteria don't exist before you start evaluating. They emerge through the act of judging. If the experts need the process to find their own standards, the model certainly can't skip it.
The loop works both ways
The teaching went in both directions.
Coaches reviewing AI responses would sometimes pause and say, "Actually, that's a better way to phrase that question." The model's attempts — even the ones that failed — surfaced patterns the coaches hadn't articulated. One coach started using a questioning technique in her own sessions that she'd first seen the AI try. She hadn't taught the model that technique. It had stumbled onto it, she recognized it was good, and she adopted it.
The eval process didn't just improve the AI. It improved the humans.
The thing we didn't plan for
Before we built the evals, our coaches, engineers, and product team each had a different idea of what "good coaching" meant. Coaches cared about emotional safety. Engineering cared about response time and hallucination rates. Product cared about whether users came back. Three definitions of "good," never reconciled.
The eval process forced the reconciliation. Everyone saying yes or no to the same outputs. To do that, they had to build a shared understanding of what they were saying yes or no to. That alignment didn't exist before. The evals created it. More on that in a future post.
The question isn't whether your AI team runs evals. It's whether the system is learning from them.
*- Rapida powered the voice infrastructure for Yuuki
Further reading
- Hamel Husain — Using LLM-as-a-Judge (Critique Shadowing methodology)
- Eugene Yan — Product Evals in Three Simple Steps (binary over Likert, Eval-Driven Development)
- RubricBench — Aligning Model-Generated Rubrics with Human Standards (why models can't create their own rubrics)
- Google DeepMind / Eedi — LearnLM Tutoring RCT (expert-supervised AI tutoring in UK classrooms)
- Construct Validity in LLM Benchmarks — 445-benchmark review (inter-rater agreement problems at industry scale)
- Harrison Chase — How Coding Agents Are Reshaping EPD (why review becomes the alignment mechanism)